If you need to extract search results for data analysis, SEO research, or automation purposes, scraping Bing is a reasonable approach, given its simple data structure and lack of strict anti-scraping measures (like CAPTCHA) compared to Google.
This tutorial will guide you through building your own Bing search results scraper in Python step-by-step. All you need to go through the tutorial is a little knowledge of the Python programming language.
If you want to speed things up and avoid writing a scraper from scratch, you can also use a ready-made Actor on Apify for free. Try Bing Search Scraper or Bing Search Result Scraper. No credit card required.
How to scrape Bing
Here are the steps you should follow to build your Bing scraper.
- Set up the environment
- Understand Bing’s structure
- Write the scraper code
- Deploy to Apify (optional)
1. Set up the environment
Here’s what you’ll need to continue with this tutorial:
- Python 3.5+: Make sure you have installed Python 3.5 or higher.
- Required libraries: You’ll only need to install the
beautifulsouplibrary by using the following command
pip install beautifulsoup4 requests
- Create a virtual environment (optional but recommended): It’s always a good practice to create a virtual environment (
venv) to isolate dependencies and avoid conflicts between packages.
python -m venv myenv
source myenv/bin/activate # On macOS/Linux
myenv\Scripts\activate # On Windows
To import the libraries to your script, use the following code
import requests
from bs4 import BeautifulSoup
2. Understand Bing’s structure
The first step of scraping any website is to understand how the information is structured. To do so, you can either right-click on any element and click “Inspect” or use the F12 key to open Developer Tools.
If you look at a sample search results page, you can see that Bing organizes its search results in a clear HTML structure:
- Each search result is contained in an
lielement with classb_algo. - Titles are in
h2tags. - Links are in
atags within theh2elements.
This clean structure makes it easy for us to scrape the information. But note that you’ll also need to write code to format the information correctly.
3. Write the scraper code
For easier usage, you should first write a function to access a search link, like https://www.bing.com/search?q=apify, mimicking a real browser request so as not to be blocked by CAPTCHA.
def scrape_bing(query):
url = f"https://www.bing.com/search?q={query}"
headers = {"User-Agent": "Mozilla/5.0"} # this is a generic user-agent;
# for better reliability, use a complete user-agent like Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36
response = requests.get(url, headers=headers)
# in case any error occurs, following code adds a print statement.
if response.status_code != 200:
print("Failed to retrieve search results")
return []
soup = BeautifulSoup(response.text, "html.parser")# parsing the data
results = [] # empty list to store the results
Then, you should write a loop to go through each of the scraped results to extract the information you want, which are titles, and the links in this case.
for item in soup.find_all("li", class_="b_algo"):
title = item.find("h2") # extracting the title
link = title.find("a")["href"] if title else "" # extracting the link
results.append((title.text if title else "No title", link))
#if title is not found, just returns the link with "No title" placeholder
return results
To run the function and print the output, write the following code:
search_results = scrape_bing("apify") # replace your search query
for title, link in search_results:
print(f"{title}: {link}")
When run, it would output the scraped data as follows:
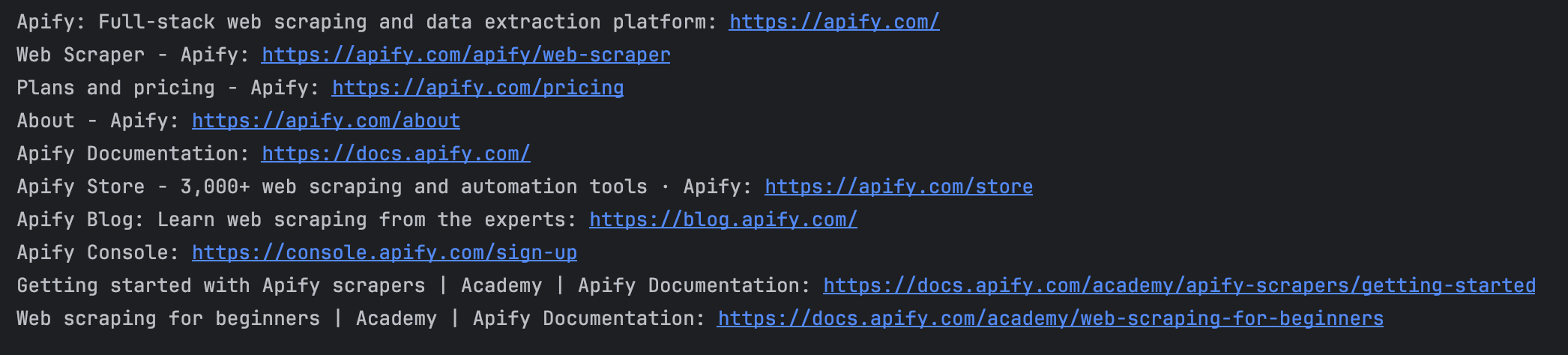
And congrats! You have successfully built a web scraper to scrape any search results page.
4. Deploy to Apify
You have built a web scraper but it can’t run automatically to track the changes over time, and the data disappears after each run since there’s no built-in storage system
However, if you deploy the scraper into a platform like Apify, you’d be able to schedule the scraper to run automatically and also store the scraped data so that you can access previously scraped data too.
To deploy your code to Apify, follow these steps:
- #1. Create an account on Apify
- #2. Create a new Actor
mkdir bing-results-scraper
cd bing-results-scraper
- Then initialize the Actor by typing
apify init. - #3. Create the main.py script
- Note that you would have to make some changes to the previous script to make it Apify-friendly. Such changes are: importing Apify SDK and updating input/output handling.
- You can find the modified script on GitHub.
- #4. Create the
Dockerfileandrequirements.txt
FROM python:3.9-slim
# Set the working directory
WORKDIR /app
# Copy the requirements file
COPY requirements.txt ./
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code
COPY . .
# Set the entry point to your script
CMD ["python", "main.py"]
beautifulsoup4==4.9.3
requests==2.25.1
apify
- #5. Deploy
- Type
apify loginto log in to your account. You can either use the API token or verify through your browser. - Once logged in, type
apify pushand you’re good to go.
- Type
Once deployed, head over to Apify Console > Your Actor > Click “Start” to run the scraper on Apify.
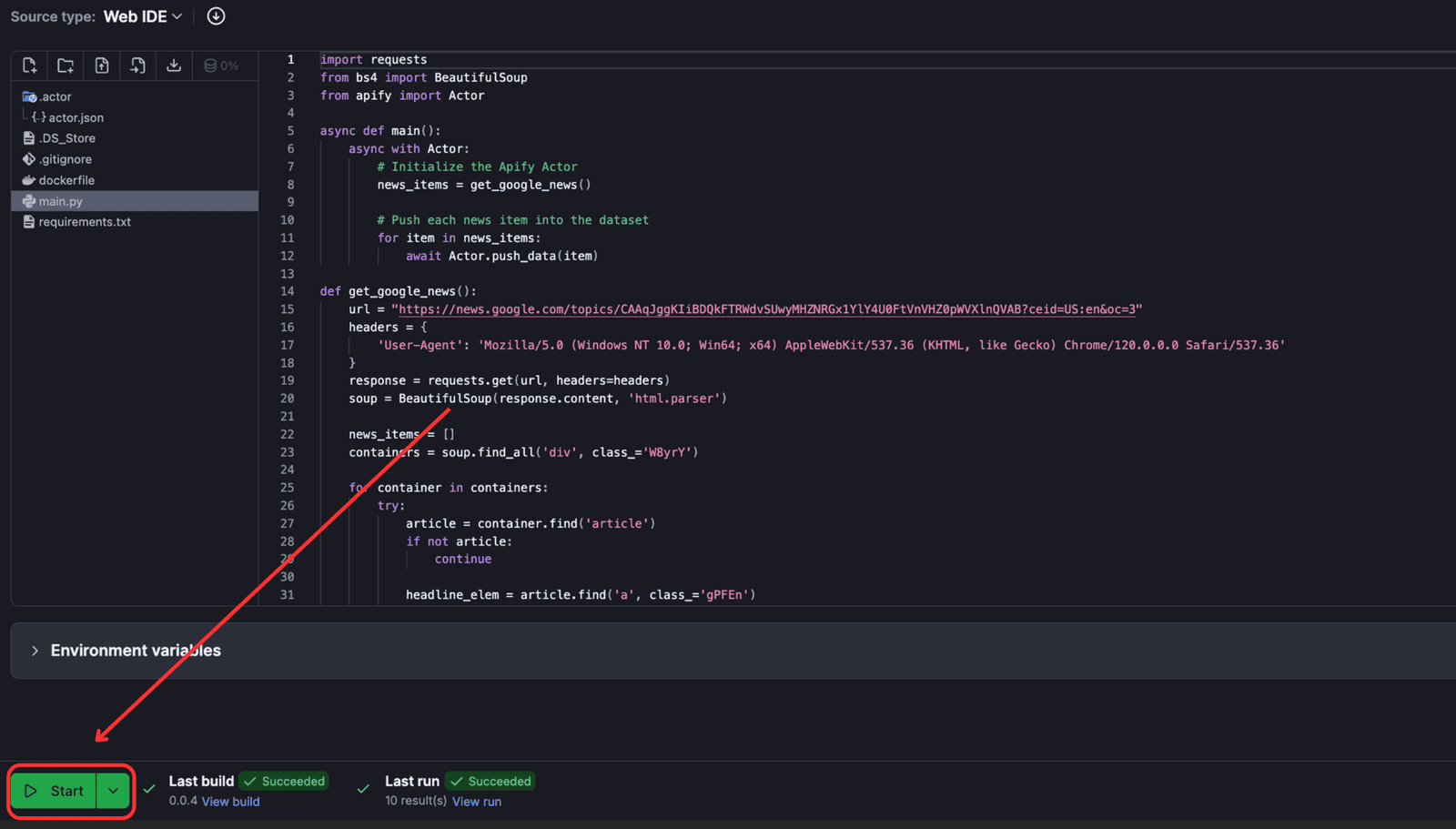
After a successful run, you can view the output of the scraper on the “Output” tab.
To view and download output, click “Export Output”.
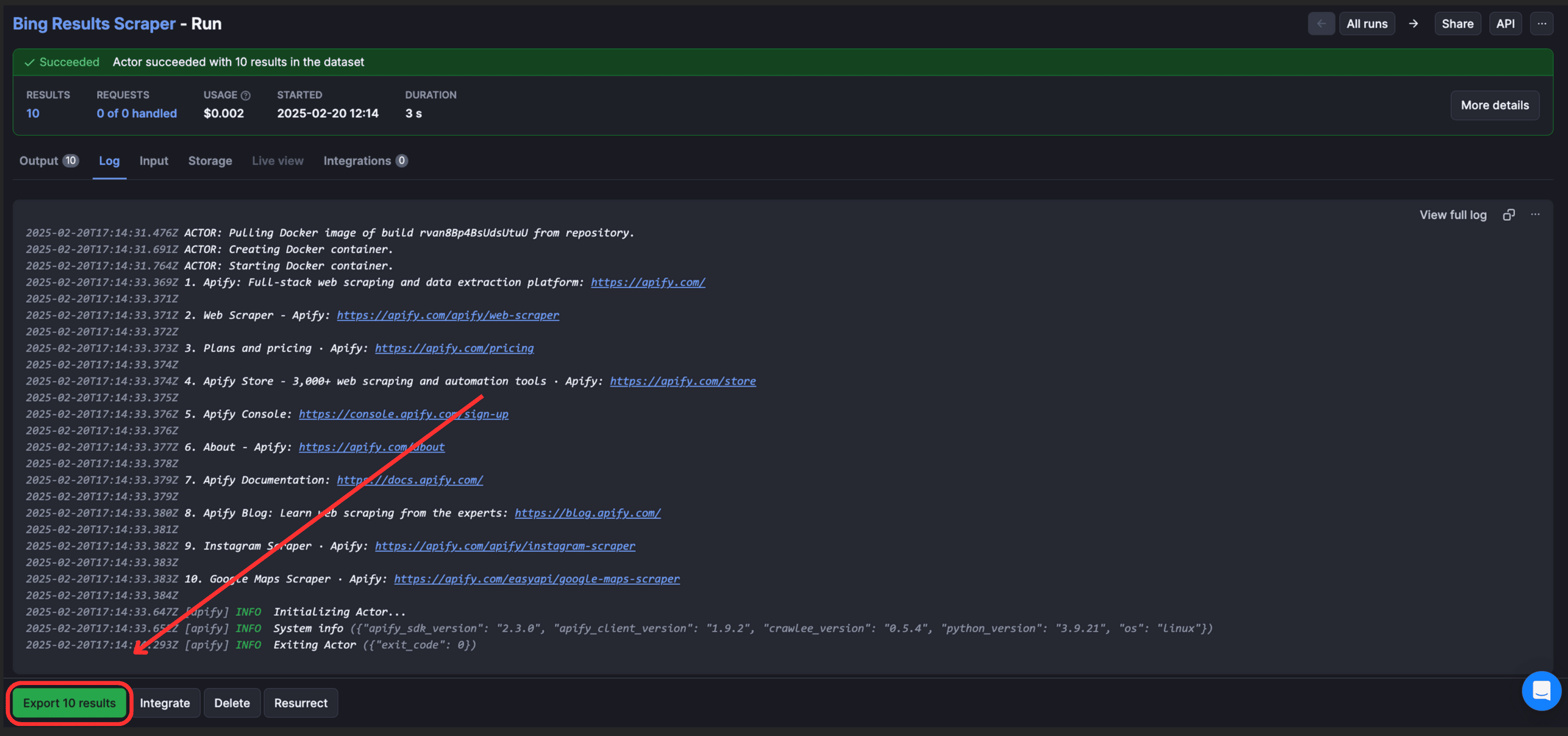
Using the export option, you can select/omit sections and download the data in different formats such as CSV, JSON, Excel, etc.
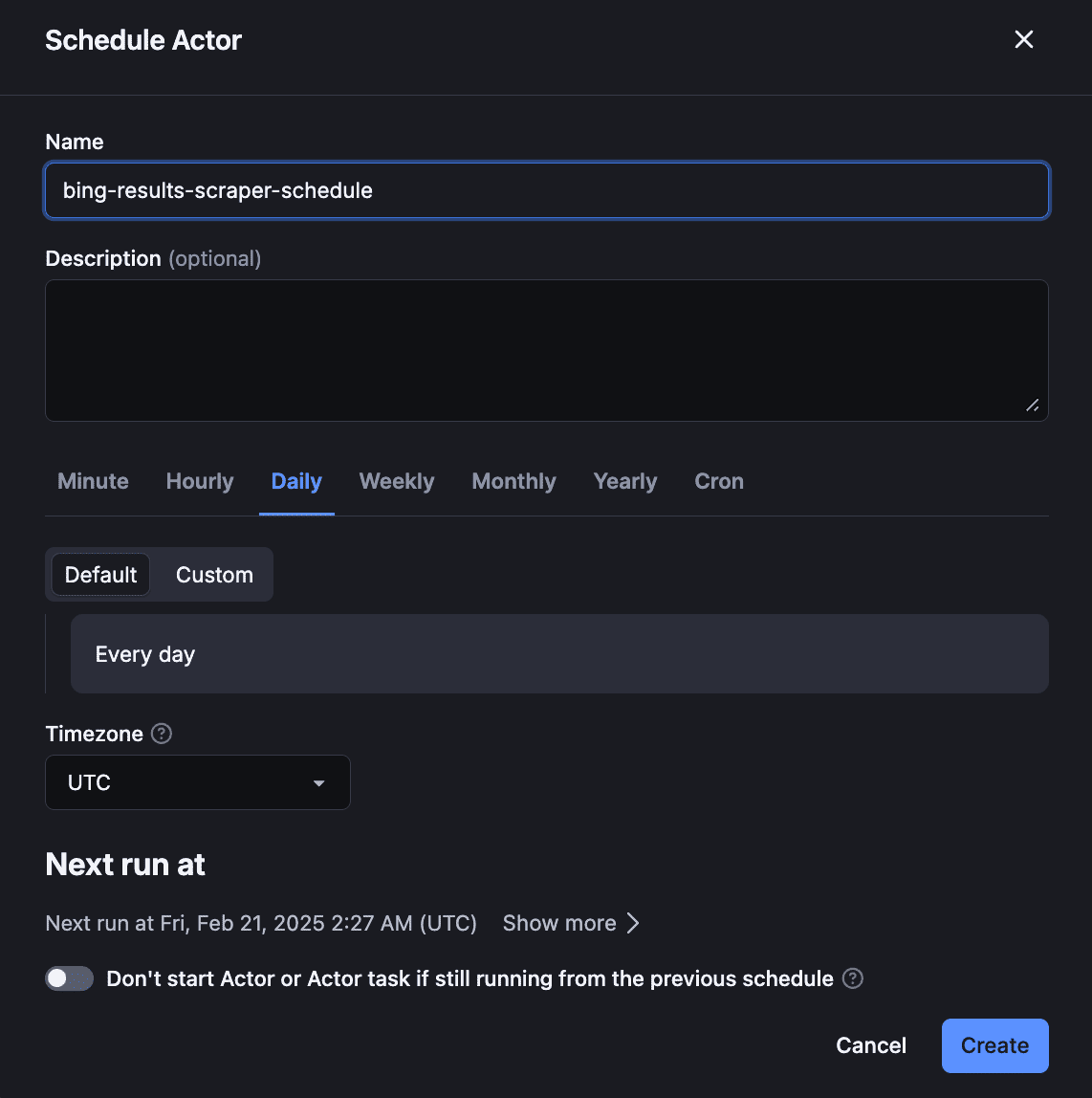
You can also schedule your Actor by clicking the three dots (•••) in the top-right corner of the Actor dashboard > Schedule Actor option.
The complete code
Following is the complete code to build your own Bing search results scraper.
import requests
from bs4 import BeautifulSoup
def scrape_bing(query):
url = f"https://www.bing.com/search?q={query}"
headers = {"User-Agent": "Mozilla/5.0"}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print("Failed to retrieve search results") # handling errors
return []
soup = BeautifulSoup(response.text, "html.parser") # parsing the info
results = [] # empty list to store data
for item in soup.find_all("li", class_="b_algo"):
title = item.find("h2") # extracting the result title
link = title.find("a")["href"] if title else "" # extracting the link
results.append((title.text if title else "No title", link))
# if title is not found, just returns the link with "No title" placeholder
return results
search_results = scrape_bing("apify") # replace your seach query
for title, link in search_results:
print(f"{title}: {link}")
Use a ready-made Bing scraper
Of course, building your own scraper is educational and offers a little flexibility but it has more downsides than upsides; handling IP blocks (as Bing detects automated requests), managing response parsing when the website structure changes, and last but not least, debugging, is some of these downsides.
The easiest way to avoid these headaches is to use a ready-made scraper on Apify. With a pre-built solution like the Bing Search Scraper, you can search results reliably and also filter by region, language, and result type.
What’s more, the output includes plain search results as well as information on the number of results, related queries, paid results, organic results, and more.
To try it out, you can go to Bing Search Scraper on Apify > Try for free, and run the Actor.
Once run, the scraper out would look like below, depending on your input:

Conclusion
In this tutorial, we built a web scraper to scrape Bing search results using Python and beautiful soup library, followed by an easy deployment on the Apify platform for easier management of the data. We also showed you an easier way to run a scraper without coding, using Apify’s ready-made scraper with advanced features.
Frequently asked questions
Can you scrape Bing’s search results?
Yes, you can scrape Bing search results using web scraping libraries like BeautifulSoup or Selenium in Python. Alternatively, you can use specialized tools or platforms, like Bing Search Result Scraper or Bing Search Scraper on the Apify platform.
Is it legal to scrape data from Bing?
Yes, it is legal to scrape data from Bing’s publicly available search results, but you should take into account local and regional laws about personal data and the website’s terms of use. Make sure your scraping is done at a reasonable rate, respect their bandwidth limits, and don’t use the data maliciously.
How to scrape Bing search results?
You can scrape Bing search results by writing a Python script using the requests library to fetch pages and BeautifulSoup to parse HTML elements. Alternatively, use a ready-made scraping tool like Apify’s Bing Search Scraper for more reliable and automated data extraction.

